
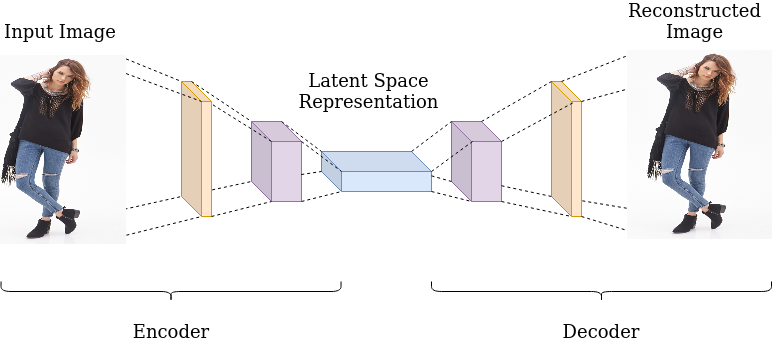
این شبکهها معماری خاصی از شبکههای عصبی هستند که از دوبخش تشکیل شدهاند، بخش اول که وظیفه فشرده کردن استخراج ویژگیهای اساسی از ورودی را دارد که به اصطلاح به آن encode گفته میشود و بخش دوم وظیفه بازسازی ورودی از ویژگیهای استخراج شده از بخش قبلی را دارد که به این قسمت decode گفته میشود. ایده اصلی شبکه های autoencoder به همین سادگی است، استخراج ویژگی در بخش اول و ساخت تصویر اصلی از ویژگی های استخراج شده در بخش دوم.
شبکههای autoencoder را یک الگوریتم یادگیری بدون نظارت میدانند که برای استخراج ویژگیهای نهفته از ورودی استفاده میکند.
ویژگیهای پنهان ورودی ممکن است به صورت مستقیم قابل مشاهده نباشند، اما نحوه توزیع دادهها را نشان میدهد. میتوان گفت در طول آموزش شبکههای autoencoder، شبکه آموزش میبیند که کدام یک از متغییرهای پنهان یک مجموعه داده که به عنوان latent space شناخته میشود، بازسازی دقیقتری از دادههای اصلی را ایجاد میکند. در واقع latent space ها تنها اطلاعات ضروری که از تصاویر ورودی دریافت شده است را شامل میشود.
به طور کلی از autoencoder ها به عنوان الگوریتمهای استخراج ویژگی مانند، فشرده سازی دادهها، حذف نویز تصویر، تشخیص ناهنجاری (anomaly detection) و تشخیص چهره استفاده میشود. همچنین انواع مختلفی از autoencoder ها مانند variational autoencoder (VAE) وautoencoder (AAE) adversarial و adapt autoencoder وجود دارد.
Autoencoders vs encoder-decoder
همه مدلهای autoencoder از encoder و decoder تشکیل شده اند اما همه encoder-decoder ها autoencoder نیستند.
encoder-decoder
معماری encoder-decoder به این صورت است که در آن یک شبکه encoder ویژگیهای کلیدی را از ورودی استخراج میکند و شبکه decoder این ویژگیهای استخراج شده را به عنوان ورودی دریافت میکند، از این چهارچوب در معماری های مختلف مانند شبکه عصبی کانولوشنی در وظایفی مانند ناحیه بندی تصویر، و در شبکههای RNN در مدل seq2seq مورد استفاده قرار میگیرد.
در معماریهای encoder-decoder ، خروجی شبکه با ورودی آن متفاوت است، اگر بخواهیم مثالی در این باره بزنیم یک شبکه ناحیه بندی تصویر مانند U-netرا در نظر بگیرید.در بخش اول این شبکه encoder، ویژگیهای را از تصویر ورودی استخراج میکند تا با استفاده از آن طبقه بندی معنایی را انجام دهد. در بخش decoder با استفاده از feature map (نقشه ویژگی) و دسته بندی پیکسلی، ماسک تصویر برای هر شی در تصویر میسازد. هدف اصلی در این مدل لیبلگذاری هر پیکسل بر اساس کلاس معنایی آن است.
از این رو میتوان گفت که این مدل به صورت نظارت شده با استفاده از ground truth آموزش و بهینه میشود تا کلاس هر پیکسل را پیش بینی کند.
Autoencoders
در مقابل autoencoder ها یک زیرمجموعه ای از encoder-decoder ها هستند که از طریق یادگیری بدون نظارت برای بازسازی دادههای ورودی آموزش داده میشوند. از آنجایی که این مدلها لیبلی برای آموزش ندارند، به جای پیشبینی الگوهای شناخته شده، الگوهای پنهان در دادهها را بررسی میکنند، اما بر خلاف روشهای بدون نظارت دیگر این شبکهها از خود دادههای ورودی به عنوان یک معیار برای اندازه گیری خروجی استفاده میکنند. به همین دلیل این مدلها learning self-supervised نامیده میشوند.
نحوه کار autoencoder
Autoencoder ها متغییرهای پنهان (latent variables) را از طریق عبور داده ها تا bottleneck قبل از رسیدن به decoder استخراج میکنند. این روش باعث میشود که encoder فقط ویژگیهای پنهانی که برای بازسازی (reconstructing) دقیق تصویر ورودی مفید است را استخراج کند.
عناصر تشکیل دهنده autoencoder
همانطور که پیشتر نیز گفته شد انواع مختلفی از autoencoder ها وجود دارند و عناصر مختلی داخل معماری آن ها وجود دارد، اما عناصر کلیدی ان ها مشترک است که عبارتند از:
Encoder
بخش اول این شبکه ها encoder است که وظیفه آن فشرده سازی دادههای ورودی از طریق کاهش ابعاد است. در یک معمای ساده شبکه encoder از لایه های پنهان شبکه عصبی تشکیل شده است که به صورت کاهشی و کمتر از لایه ورودی به تدریج کمتر میشود. همانطور که دادهها از این لایهها عبور میکنند فرایند فشرده سازی (squeezing) نیز انجام میشود و به ابعاد کمتری فشرده میشوند.
bottleneck
گلوگاه یا bottleneck حاوی فشرده ترین representation در دو سر شبکه یعنی بخش encoder و بخش decoder است. پیشتر نیز گفته شد که هدف اصلی در بهش encoder استخراج مهمترین و حداقل تعداد ویژگی های است که به توان با استفاده از آنها دادههای ورودی را بازسازی کرد. ویژگیهای که از این بخش خارج میشوند وارد decoder خواهند شد.
Decoder
این بخش از معماری همانند بخش encoder از لایههای پنهان شبکه عصبی تشکیل شده است اما برعکس لایههای encoder ، به صورت تدریجی افزایش پیدا میکند و ویژگیهای بخش bottleneck را از حالت فشرده خارج میکند و به حالت اولیه بازسازی میکند.
بعد از بازسازی دادهها، خروجی با ground truth مقایسه میشود تا کارایی autoencoder سنجیده شود. خطای بین داده خروجی و ground truth را خطای بازسازی (reconstruction error) میگویند.
در بعضی موارد همانند شبکههای GAN بخش decoder کنار گذاشته میشود و فقط از بخش encoder استفاده میشود. در بسیاری از مواقع شبکه decoder همچنان به آموزش (post-training) ادامه میدهد. مانند شبکه های VAE که در آن شبکه خروجی جدید تولید میکند.
مزایایی استفاده از شبکه خودرمزنگار
یکی از مهمترین مزیتهای استفاده از شبکههای autoencoder نسبت به شبکه های دیگر مانند PCA استخراج همبستگی های غیر خطی و پیچیده تر است. دلیل آن نیز استفاده از توابع فعال سازی غیر خطی مانند سیگموئید در لایههای آن است.
طراحی یک autoencoder
انواع مختلف autoencoder ها معمولا از این ساختار که گفته شد تبعیت میکنند، علاوه بر نوع شبکه عصبی انتخاب شده مانند شبکه عصبی کانولوشنی، RNN ها مانند LSTM ، معماری های transformer چندین هایپرپارامتر دیگر نیز در طراحی شبکهها مهم هستند که عبارتند از:
- Bottleneck size: اندازه bottleneck تعیین کننده حد فشرده سازی دادههاست، همچنین میتواند به عنوان یک regularization استفاده شود که یکی از راه های مقابله با overfitting یا underfitting است.
- تعداد لایه ها: عمق یک شبکه autoencoder را با تعداد لایههای encoder و decoder اندازه گیری میکنند. عمق بیشتر میتواند باعث پیچیدگی بیشتر شود در حالی که عمق کمتر سرعت پردازش را بیشرت میکند.
- تعداد نرون های هر لایه: به طور کلی در بخش encoders تعداد نرون ها با هر لایه کاهش مییابد و در بخش bottleneck به حداقل میرسد و در مقابل با هر لایه decoder افزایش مییابد.(همیشه این قاعده وجود ندارد به طور مثلا در شبکه های sparse autoencoder تعداد نرون ها متفاوت است یا این که در شبکههای که با تصاویر بزرگ کار میکنند، تعداد نرون های بیشتری نیاز دارد تا زمانی که تصاویر کوچک هستند.
- Loss function: به طور کلی این تابع خطای بازسازی بین خروجی و ورودی را اندازه گیری میکند، برای بهینه سازی وزن های مدل از gradient descent در طول backpropagation استفاده میشود. الگوریتم های ایده ال برای loss function نیز به فراخور وظیفه ای که autoencoder دارد تعریف میشود.