
امروزه الگوریتمهای یادگیری ماشین و به خصوص یادگیری عمیق را در خیلی از حوزهها مانند سلامت و پزشکی، صنعت و تولید و همچنین مالی مورد استفاده قرار میگیرد به زبان دیگر میشود گفت که مردم به شدت مشتاق هستند که از قدرت هوش مصنوعی در جنبههای کلیدی زندگی خود استفاده کنند. اما استفاده از هوش مصنوعی بدون این که اعتماد کافی به مدل و روش کار آن و همچنین توضیح رفتار آن بسیار دشوار است، به خصوص زمانی که شبکههای یادگیری عمیق به عنوان یک جعبه سیاه که داخل آن قابل توضیح نیست ارائه میشوند.
برای آشنایی بهتر با اهمیت موضوع موارد زیر را در نظر بگیرید:
- صنعت مالی تحت نظارت شدید است و موسسات مالی و بانکی موظف هستند که طبق قانون تصمیمات منصفانهای بگیرند، به طور مثلا در زمان اعتبارسنجی خود باید توضیح دهند که چرا تصمیم به رد درخواست وام گیرنده گرفتهاند و دلایل خود را ارائه دهند.
- در بخش سلامت و پزشکی، مدلها مسئولیت جان انسانها را بر عهده دارند. چگونه ما میتوانیم اعتماد کافی به مدلهای black-box داشته باشیم تا مسئولیت مریضها را به آن بدهیم.
- تصور کنید یک مدل تصمیمگیری کیفری دارید که میتواند خطر تکرار جرم را پیشبینی کند، باید مطمئن باشیم که مدل به شیوهای منصفانه و بدون تبعیض رفتار میکند.
- یک ماشین خودران در یک لحظه یک رفتار غیر متعارف از خود نشان میدهد و ما نمیتوانیم بفهمیم چرا؟ آیا انقدر به این تکنولوژی اعتماد داریم که بخواهیم کنترل خودرو را در یک ترافیک سنگین واقعی به دست آن بسپاریم؟
مدل های تفسیرپذیر
در سال2017 مقالهای با عنوان افسانه تفسیرپذیری مدلها منتشر شد( شما میتوانید این مقاله را در این لینک بخوانید) که اگر بخواهیم به طور خلاصه بگویم در این مقاله چه گفته شده است باید بگویم :
یک انسان میتواند فرآیند محاسبه با درک کامل از الگوریتم( شفافیت الگوریتمی) تکرار کند ( شبیهساز پذیری) ، و در نهایت هر بخش جداگانه از مدل دارای یک توضیح شهودی است ( تجزیه پذیری).
بسیاری از مدلهای کلاسیک ساختار نسبتا سادهای دارند و با یک روش ساده نیز میتوان آنها را تفسیر کرد، از طرف دیگر ابذارهای برای تفسیرپذیری مدلها در حال توسعه است.
در ادامه به بررسی تفسیرپذیری مدلهای مختلف میپردازیم:
Regression
رابطه کلی رگرسیون خطی به صورت زیر تعریف میشود:
y = w0 + w1x1 + w2x2+ …. + wnxn
در یک مدل رگرسیون، هر ضریب (coefficient) نشاندهنده میزان تغییر پاسخ (متغیر وابسته) در ازای یک واحد افزایش در متغیر مستقل مربوطه است، در حالی که سایر متغیرها ثابت نگه داشته میشوند. اما این ضرایب بهصورت مستقیم قابل مقایسه با یکدیگر نیستند، زیرا واحد اندازهگیری و مقیاس متغیرها متفاوت است؛ مثلاً یک واحد افزایش در سن (یک سال) با یک واحد افزایش در درآمد (مثلاً یک میلیون تومان) قابل مقایسه نیست. برای اینکه بتوان تأثیر نسبی و اهمیت ویژگیها را با هم مقایسه کرد، لازم است ابتدا متغیرها استاندارد شوند؛ یعنی به مقیاسی یکسان تبدیل شوند. این کار را میتوان با ابزارهایی مانند StandardScaler یا RobustScaler در کتابخانه Scikit-learn انجام داد. با این کار، ضرایب بهصورت نسبی قابل مقایسه خواهند بود. با این حال، حتی اگر متغیرها استاندارد نشده باشند، میتوان حاصلضرب مقدار هر ویژگی در ضریب آن (w * x) را محاسبه کرد تا فهمید که آن ویژگی در حالت خاصِ آن داده، چه اندازه در نتیجه مدل مؤثر بوده است.
Naive Bayes
این الگوریتم یک فرض ساده دارد که ویژگیها مستقل از یکدیگر هستند هر کدام به طور مستقل در خروجی مشارکت دارند. در مدل طبقهبندی Naive Bayes، هدف این است که احتمال تعلق یک نمونه داده (که با یک بردار ویژگیها نمایش داده میشود) به یک کلاس خاص را محاسبه کنیم. این مدل بر پایه قانون بیز عمل میکند و میگوید که احتمال تعلق داده به کلاس c با توجه به ویژگیهای آن X = [x1, x2, …, xn]، برابر است با حاصلضرب احتمال شرطی ویژگیها با توجه به کلاس (P(x∣c در احتمال اولیه آن کلاس (P(c ، تقسیم بر احتمال کلی داده (P(x . اگر بخواهیم این را به زبان ریاضی بگویم میتوانیم از رابطه زیر استفاده کنیم:
p(c|xi) =p(c)p(xi|c)p(xi)
در عمل چون( P(x برای همه کلاسها یکسان است، فقط صورت کسر در تصمیمگیری نقش دارد.
در مرحله آموزش، مدل Naive Bayes احتمال اولیه هر کلاس را بر اساس توزیع دادهها یاد میگیرد. سپس در زمان پیشبینی، با استفاده از این احتمال اولیه و احتمال وقوع هر ویژگی در هر کلاس، احتمال نهایی یا posterior را برای هر کلاس محاسبه میکند. این احتمال نهایی، نشان میدهد که با توجه به ویژگیهای داده، چقدر محتمل است که آن داده به یک کلاس خاص تعلق داشته باشد و از این طریق میتوان تأثیر هر ویژگی را در تصمیم مدل بررسی کرد.
Decision Tree
مدلی ساده و قابل تفسیر برای دستهبندی دادههاست که از مجموعهای از شرطهای منطقی بهصورت if…then…else ساخته میشود. هر شرط، بر پایهی یک یا چند ویژگی، بررسی میکند که آیا دادهای خاص به یک کلاس تعلق دارد یا نه، و بهمحض اینکه یکی از شرطها برقرار شود، مدل تصمیم نهایی را اعلام میکند. این ساختار زنجیرهای باعث میشود که خروجی مدل برای انسان بهراحتی قابل درک باشد و بتوان دلیل تصمیمگیری مدل را بهوضوح بیان کرد. به همین دلیل، decision listها بهویژه در حوزههایی مانند پزشکی که شفافیت و تفسیرپذیری تصمیمات بسیار حیاتی است، کاربرد گستردهای دارند. همچنین میتوان این مدلها را بهصورت گرافیکی در قالب درخت تصمیم نیز نمایش داد تا تحلیل آنها آسانتر شود. مثال زیر یک نمونه از زنجیره شرطهای است که در این مدل استفاده میشود را نشان میدهد:
if (age > 60 and smoker == True): then high risk
else if (blood_pressure > 140): then medium risk
else: low risk
در هر خط یکی از شروط بررسی میشود و در صورتی که شرط برقرار باشد، تصمیم گیری انجام میشود و ادامه دیگر بررسی نمیشود. به طور کلی میتوان گفت که برای افزایش تفسیرپذیری تصمیمات مدل سه روش وجود دارد که عبارتند از:
لیستهای قانون نزولی (Falling Rule Lists)
مدلی است که توسط Wang و Rudin در سال ۲۰۱۵ معرفی شد(در این لینک میتوانید آن را مطالعه کنید). نحوه عملکرد این مدل به اینگونه است که هر چقدر لیست شروطی که باید بررسی شود به پایین حرکت کند، احتمال تعلق داده به کلاس هدف کاهش مییابد. به زبان دیگر لیست از قویترین قوانین( با بیشترین احتمال) در بالا شروع میشود و هرچه به سمت پایین حرکت میکند قوانین ضعیفتر میشود.این ساختار باعث میشود که تصمیمگیری مدل هم قابل تفسیر باشد هم قابل اطمینان.
لیستهای قانون بیزی (Bayesian Rule Lists)
مدلی است که توسط Letham و همکاران در سال ۲۰۱۵ معرفی شد( در این لینک میتوانید مقاله را مطالعه کنید). این مدل به جای تولید یک لیست از شروط که بر اساس آن بتوان تصمیم گرفت، از دیدگاه آمار بیزی به صورت مسئله نگاه میکند و توزیعی از شروط ممکن را بر اساس دادهها تولید میکند، در نتیجه خروجی این مدل مجموعهای از شروط است با احتمالات مختلف. با این کار عدم قطعیت که در بسیاری از حوزهها مانند کاربردهای پزشکی نیز در نظر گرفته میشود.
مجموعه تصمیم قابل تفسیر (Interpretable Decision Sets)
این مدل در سال ۲۰۱۶ توسط Lakkaraju، Bach و Leskovec ارائه شد( اصل مقاله را در این لینک میتوانید مطالعه کنید.)، از مجموعهای از قوانین مستقل استفاده میکند. هر قانون میتواند بهطور مستقل برای تصمیمگیری استفاده شود و این انعطافپذیری بالاتری نسبت به لیستهای خطی ایجاد میکند. نکته مهم درباره IDS این است که هنگام آموزش، هم دقت مدل و هم تفسیرپذیری قوانین را بهطور همزمان بهینهسازی میکند. به همین دلیل، IDS یک چارچوب متعادل بین مدلهای دقیق و مدلهای قابل فهم است. همچنین این روش به روش BETA برای تفسیر مدلهای پیچیده (black-box) شباهت دارد که در ادامه متن به آن اشاره خواهد شد.
Random Forest
خیلیها فکر میکنند که مدل جنگل تصادفی یا (Random Forest) مثل یک جعبه سیاه عمل میکند. یعنی نمیشود فهمید چطور به جوابهایش میرسد. اما این یک غلط رایج است و دلیل اصلی آن این است که جنگل تصادفی از تعداد زیادی “درخت تصمیم” تشکیل شده است. حالا بیایید ببینیم این یعنی چه:
درختان تصمیم به خودی خود قابل فهم هستند: هر درخت تصمیم مثل یک نمودار است که با یک سری سوالهای “اگر … آنگاه …” به یک نتیجه میرسد. مثلاً: “اگر هوا آفتابی است و دمای هوا بالای ۲۵ درجه است، آنگاه برویم شنا.” دنبال کردن این مسیرها در یک درخت تصمیم ساده است و میتوان فهمید چرا یک تصمیم خاص گرفته شده.
جنگل تصادفی، مجموعهای از این درختان قابل فهم است: جنگل تصادفی، پیشبینی نهایی خود را با ترکیب نتایج تعداد زیادی از همین درختان تصمیم (که هر کدام به طور مستقل آموزش دیدهاند) به دست میآورد. معمولاً نتیجهای که بیشتر درختها به آن رأی دادهاند، به عنوان خروجی نهایی انتخاب میشود. پس اگر تکتک درختها قابل فهم باشند، منطقی است که کل مجموعه هم تا حد زیادی قابل درک باشد.
نحوه محاسبه اهمیت ویژگیها در جنگل تصادفی
اگر هر بار فقط یک درخت را در نظر بگیریم، به راحتی میتوانیم ببینیم کدام ویژگیها (مثلاً در مثال بالا، “وضعیت هوا” یا “دمای هوا”) نقش مهمتری در تصمیمات آن درخت خاص داشتهاند.
تفسیر مدلهای black box
بسیاری از مدلهای یادگیری ماشین، بهویژه مدلهای قدرتمند مانند شبکههای عصبی عمیق، بهگونهای طراحی نشدهاند که خروجیها و تصمیماتشان بهراحتی قابل تفسیر باشند؛ به این مدلها “جعبهسیاه” یا black box گفته میشود. در این شرایط، روشهایی برای توضیح و تفسیر این مدلها توسعه داده شدهاند که بدون نیاز به دانستن جزئیات داخلی مدل، سعی میکنند با تحلیل رفتار مدل آموزشدیده، دلایل پشت یک پیشبینی خاص را توضیح دهند. این رویکرد، یعنی مستقل بودن فرآیند تفسیر از ساختار داخلی مدل، در کاربردهای واقعی بسیار مفید است؛ چون حتی اگر خود مدل در طول زمان تغییر کند یا بهروزرسانی شود، موتور تفسیر (explanation engine) همچنان میتواند با آن کار کند. از طرفی، وقتی هدف صرفاً افزایش دقت مدل باشد، دیگر نگران تفسیرپذیری نیستیم و میتوانیم با افزودن پارامترهای بیشتر و محاسبات غیرخطی پیچیده، قدرت مدل را افزایش دهیم؛ دقیقاً همان کاری که در شبکههای عصبی عمیق انجام میشود و باعث موفقیت آنها در کار با دادههای پیچیده مثل تصاویر، صدا و متن شده است. با این حال، در مواردی که تصمیم مدل حیاتی یا حساس است مثل تشخیص بیماری یا تصمیمات قضایی سؤال کلیدی این است: آیا میتوان به این مدل اعتماد کرد؟ و پاسخ به این سؤال، هدف اصلی از ارائهی توضیح برای مدلهای جعبهسیاه است. در طراحی چارچوبهای تفسیر مدلهای یادگیری ماشین، باید تعادلی میان دو هدف کلیدی برقرار شود: وفاداری (Fidelity) و تفسیرپذیری (Interpretability).
وفاداری به این معناست که خروجی حاصل از توضیح یا تفسیر باید تا حد امکان با پیشبینی اصلی مدل مطابقت داشته باشد؛ یعنی اگر مدل اصلی میگوید “بله”، توضیح هم باید همان را نشان دهد و نه چیز متناقض.
از طرفی، تفسیرپذیری به این معناست که توضیح ارائهشده باید بهاندازهای ساده و واضح باشد که یک انسان (حتی بدون دانش تخصصی) بتواند آن را درک کند. اگر تفسیر خیلی پیچیده باشد در عمل کارآمد نخواهد بود.
بنابراین، بهترین چارچوبهای تفسیر آنهایی هستند که هم دقت توضیحشان بالا باشد و هم قابل فهم باقی بمانند. در ادامه، سه روش معرفی خواهند شد که برای تفسیر محلی (local interpretation) طراحی شدهاند، یعنی تمرکزشان بر توضیح پیشبینی مدل برای یک نمونه خاص از دادههاست، نه کل مدل.
تجزیه پیش بینی
تجزیه پیشبینی یک روش برای توضیح پیشبینی مدل روی یک نمونه خاص است. ایدهی اصلی این روش این است که برای درک نقش هر ویژگی (Feature) در پیشبینی نهایی مدل، باید اثر حذف آن ویژگی را بررسی کنیم. بهعبارت ساده، ابتدا مدل را روی نمونه اصلی اجرا میکنیم و احتمال تعلق آن به یک کلاس خاص (مثلاً “زنده ماندن در تایتانیک”) را اندازه میگیریم. سپس، همان نمونه را دوباره به مدل میدهیم اما با حذف یا نادیده گرفتن یک ویژگی (مثلاً “جنسیت”) و تفاوت دو پیشبینی را محاسبه میکنیم. این اختلاف، نشاندهندهی میزان تأثیر آن ویژگی بر تصمیم مدل است. اگر مدل بهصورت مستقیم احتمال خروجی بدهد (مانند درخت تصمیم یا logistic regression)، محاسبه این اختلاف ساده است. اما اگر خروجی مدل نمره یا امتیاز باشد (مثل SVM یا بعضی از مدلهای پیچیده)، نیاز به کالیبراسیون خروجی داریم تا آن را به احتمال تبدیل کنیم، که خود یک لایهی اضافی به مدل اضافه میکند و تفسیر را پیچیدهتر میکند.
یک چالش دیگر این است که وقتی ویژگی را حذف میکنیم، باید مقدار آن را به نوعی جایگزین کنیم—مثلاً با None یا NaN— اما مدلها این مقادیر را به روشهای مختلف تفسیر میکنند (مثلاً جایگزینی با میانگین یا مقدار خاص)، و این میتواند به نتایج متفاوت منجر شود. برای حل این مشکل، دانشمندان پیشنهاد دادهاند که بهجای حذف ویژگی، تمام مقادیر ممکن آن ویژگی (در دادههای آموزشی) را امتحان کنیم و پیشبینی مدل را برای هر حالت محاسبه کرده، سپس میانگینگیری کنیم، طوری که وزن هر مقدار متناسب با احتمال وقوعش در داده باشد. این فرآیند باعث میشود اثر واقعی ویژگی بهشکل آماری دقیقتر اندازهگیری شود.
در نهایت، با اندازهگیری اثر حذف هر ویژگی بهتنهایی، میتوانیم اثر نسبی هر ویژگی بر پیشبینی نهایی مدل را تجزیه کنیم. مثلاً در مثالی از دیتاست تایتانیک، برای پیشبینی شانس زنده ماندن یک مسافر مرد بالغ درجهیک، مشخص شده که «مرد بودن» تأثیر منفی زیادی دارد، درحالیکه «مسافر درجه یک بودن» تأثیر چشمگیری ندارد. این اطلاعات بهصورت نمودار میلهای نمایش داده میشود، که میلههای تیره تأثیر واقعی ویژگی روی نمونه خاص هستند، و میلههای روشنتر میانگین تأثیر مثبت و منفی آن ویژگی در کل داده هستند. این روش باعث میشود بفهمیم کدام ویژگیها واقعاً در تصمیمگیری مدل نقش داشتهاند، و به چه میزان.
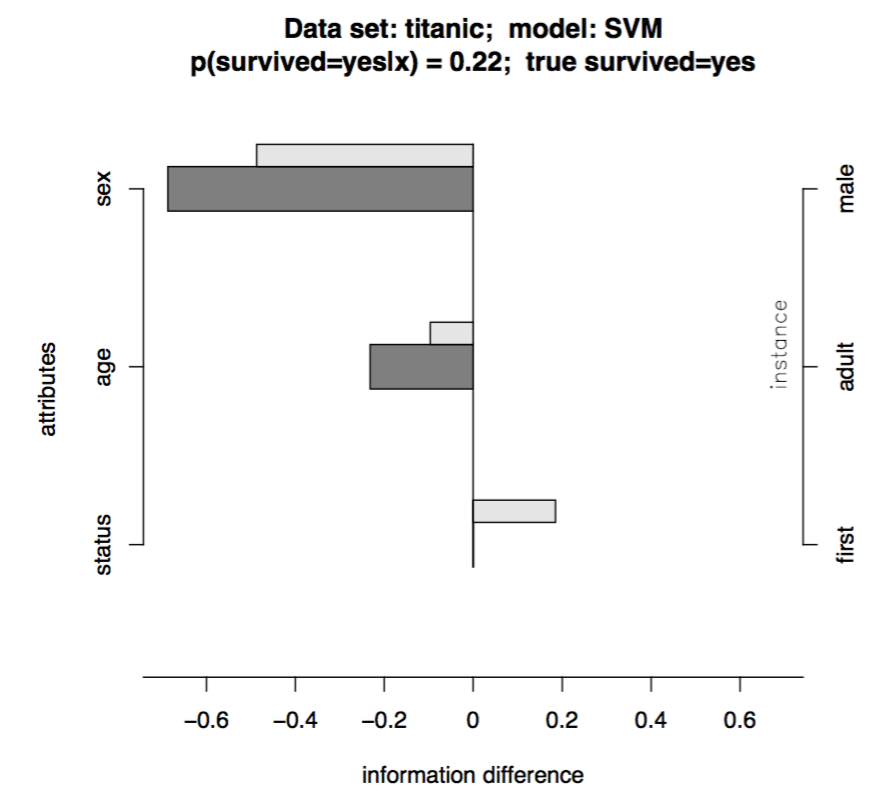
Local Gradient Explanation Vector
این روش برای تفسیر محلی پیشبینیهای مدلهای طبقهبندی پیچیده (بهخصوص غیرخطی) توسط Baehrens و همکاران در سال 2010 ارائه شده است( میتوانید اصل مقاله را در این لینک بخوانید). این روش برای مدلهای طبقهبندی غیرخطی است که میخواهد بفهمد برای تغییر خروجی مدل، باید یک داده چطور تغییر کند. در این روش بهجای تحلیل کل مدل، فقط به رفتار مدل در اطراف یک نقطهی خاص (نمونه تست) نگاه میکند و از گرادیان محلی (local gradient) استفاده میشود. ایدهی اصلی این است:
اگر مدل برای نمونهای مثلاً کلاس A را پیشبینی کرده، باید بررسی کنیم اگر بخواهیم پیشبینی به کلاس B تغییر کند، داده چطور باید تغییر کند. این اطلاعات در قالب یک بردار گرادیان بیان میشود که به هر ویژگی یک مقدار میدهد؛ اگر مقدار بزرگ و مثبت باشد، یعنی افزایش آن ویژگی احتمال کلاس فعلی را کاهش میدهد، و اگر منفی باشد، افزایش آن ویژگی باعث تقویت کلاس فعلی میشود.
اما این روش فقط زمانی مستقیم قابل استفاده است که خروجی مدل، احتمال (probability) باشد (مثل Logistic Regression یا Gaussian Process Classifier). در غیر این صورت، باید ابتدا خروجی مدل را کالیبره کنیم یا از یک مدل جایگزین استفاده کنیم که شبیه رفتار مدل اصلی باشد ولی خروجیاش احتمال باشد.
برای انجام این کار، نویسندگان پیشنهاد دادهاند که از یک روش آماری به نام Parzen Window Estimation استفاده کنیم. این روش به ما کمک میکند تا چگالی کلاسها (class densities) را تخمین بزنیم. مراحل کلی به این صورت است:
- ابتدا با استفاده از مدل اصلی (حتی اگر فقط برچسب کلاس خروجی بدهد)، به هر دادهی آموزش یک کلاس اختصاص میدهیم.
- سپس، با استفاده از تابع کرنل (مثل Gaussian Kernel)، تخمینی از چگالی دادهها برای هر کلاس به دست میآوریم.
- بعد از آن، با استفاده از قانون بیز (Bayes Rule)، احتمال تعلق به هر کلاس را برای نقاط جدید محاسبه میکنیم.
- در نهایت، این احتمالها را برای محاسبهی گرادیان در نقطهی موردنظر استفاده میکنیم.
با این روش میتوان یک بردار تفسیر محلی (local explanation vector) به دست آورد که نشان میدهد هر ویژگی چقدر در تصمیم مدل نقش داشته و جهت تغییرش برای تغییر تصمیم چیست.
Local Interpretable Model-Agnostic Explanations
LIME روشی است که هدفش تفسیر پیشبینی یک مدل پیچیده فقط در اطراف یک نقطهی خاص از دادهها است. یعنی به جای اینکه کل مدل را بفهمیم، فقط میخواهیم بفهمیم چرا مدل برای یک دادهی خاص، خروجی خاصی داده است. خوبی LIME این است که مستقل از نوع مدل است (model-agnostic)، یعنی میتواند برای هر نوع مدلی استفاده شود (مثلاً شبکه عصبی، SVM، درخت تصمیم و …).
مراحل کار LIME:
تبدیل داده به نمایشی قابل تفسیر (Interpretable Representation): در این مرحله، داده را به شکلی سادهتر تبدیل میکنیم که انسان بتواند آن را بهتر درک کند:
برای متنها: هر ویژگی نشاندهندهی وجود یا عدم وجود یک کلمه است (بردار باینری).
برای تصاویر: تصویر به نواحی مشابه (سوپرپیکسلها) تقسیم میشود و هر ویژگی نشاندهندهی وجود یا عدم وجود آن ناحیه است.
ایجاد دادههای مصنوعی اطراف نمونهی موردنظر: کاری که LIME میکند این است که دادهی اصلی را کمی دستکاری میکند (مثلاً حذف چند کلمه یا تار کردن بعضی بخشهای تصویر) و از مدل میپرسد که برای هر نسخهی جدید چه پیشبینیای دارد. این کار را چندین بار تکرار میکند و مجموعهای از دادههای مشابه با خروجی مدلشان جمعآوری میکند.
یادگیری یک مدل ساده برای تخمین رفتار مدل اصلی در اطراف آن نقطه: حالا که کلی نمونهی مشابه و خروجیشان داریم، LIME یک مدل ساده (مثل رگرسیون خطی با LASSO) را آموزش میدهد که فقط در همان ناحیه اطراف نقطهی موردنظر دقیق باشد. این مدل ساده میگوید که کدام ویژگیها در این پیشبینی خاص بیشترین تأثیر را داشتهاند.
وزندهی به دادهها بر اساس فاصلهشان از نقطهی اصلی: در آموزش مدل توضیحدهنده، به دادههایی که به نقطهی اصلی نزدیکتر هستند وزن بیشتری داده میشود. یعنی LIME تمرکز خود را فقط روی اطراف نقطه نگه میدارد.
در مقالهی اصلی، از LIME برای تحلیل یک مدل SVM متنکاو استفاده کردند که وظیفهاش تشخیص متنهای مربوط به “مسیحیت” و “آتئیسم” بود. مدل دقت بسیار خوبی داشت (94٪ روی دادههای تست)، اما وقتی با LIME بررسی شد، مشخص شد که تصمیمات مدل بر اساس کلماتی مثل “re”، “posting” و “host” گرفته شدهاند—کلماتی که هیچ ربط مفهومی به موضوع ندارند! این نشان داد که مدل فقط الگوهای سطحی و اشتباه یاد گرفته و قابل اعتماد نیست، با وجود دقت ظاهری بالا.
Black Box Explanation through Transparent Approximations
این روش که به اختصار BETA نامیده میشود، توضیح یک مدل پیچیده به کمک مدل شفاف و سادهای که آن را تقریب میزند.
این روش با الهام از روش Interpretable Decision Sets طراحی شده و هدف آن ساختن یک مجموعهی کوچک از قوانین تصمیمگیری ساده است که بتوانند رفتار مدل اصلی را تا حد زیادی بازسازی کنند، بهطوری که برای انسان قابل درک باشد.
ساختار خروجی مدل BETA:
BETA یک مجموعهی دو-سطحی از قوانین تصمیمگیری میسازد. هر قانون (rule) یک بخش از رفتار مدل را بهصورت واضح و بدون ابهام توضیح میدهد. مثلاً یک قانون ممکن است اینطور باشد:
اگر (سن > 60) و (جنسیت = مرد) و (فشار خون بالا)، آنگاه پیشبینی مدل: “بیمار در معرض خطر است.”
هر قانون، یک بخش مشخص از رفتار مدل را پوشش میدهد و با قوانین دیگر تداخل زیادی ندارد.
نویسندگان BETA یک تابع هدف جدید (objective function) طراحی کردهاند که سه معیار اصلی را همزمان بهینه میکند:
- Fidelity (وفاداری):
توضیحاتی که BETA تولید میکند باید تا حد زیادی با خروجی مدل اصلی همخوان باشند، یعنی مدل ساده تقریب خوبی از مدل اصلی باشد. - Unambiguity (عدم ابهام):
قوانین تصمیمگیری نباید با هم تداخل زیادی داشته باشند. هر قانون باید ناحیهای مجزا از رفتار مدل را پوشش دهد تا توضیحات روشن و قابل تفسیر باقی بمانند. - Interpretability (قابلیت تفسیر):
مجموعهی قوانین باید ساده، کوچک و سبک باشد تا انسان بتواند آن را بخواند و درک کند. تعداد قوانین و پیچیدگی هر قانون باید محدود باشد.
این سه ویژگی با هم در قالب یک تابع هدف ریاضی ترکیب شدهاند، و BETA سعی میکند در فرایند آموزش خود این تابع را بهینه کند.
Explainable Artificial Intelligence
با پیشرفت سریع روشهای یادگیری عمیق (Deep Learning)، نگرانیهایی دربارهی شفافیت و قابل اعتماد بودن تصمیمات مدلها به وجود آمده است، چرا که ساختار پیچیده، تعداد بسیار زیاد پارامترها و عملیات ریاضی غیرخطی باعث شدهاند مدلهای عمیق به جعبه سیاه (black box) تبدیل شوند؛ یعنی ما نمیدانیم دقیقاً چگونه تصمیم میگیرند. این همان مشکلی است که پروژهی XAI (هوش مصنوعی قابل توضیح) از سازمان DARPA قصد دارد آن را حل کند. هدف این پروژه توسعهی مدلهایی است که نهتنها قدرتمند باشند، بلکه قابل درک و توضیح برای انسان نیز باشند؛ تا انسان بتواند به آنها اعتماد کند و تصمیماتشان را مدیریت کند. مطالعات روی حملات خصمانه (Adversarial Examples) نشان دادهاند که مدلها ممکن است در برابر تغییرات کوچک و نامحسوس در ورودی، رفتارهای غیرمنتظره و خطرناک از خود نشان دهند، بدون اینکه بدانیم چرا. برای نمونه، شرکت Nvidia سیستمی طراحی کرده که با برجستهسازی پیکسلهای مهم در تصاویر ورودی، نشان میدهد مدل خودران چه بخشهایی از تصویر را برای تصمیمگیری مهم میداند؛ اگر این نقاط با درک انسانی همخوانی داشته باشند، میتوانیم راحتتر به مدل اعتماد کنیم. بنابراین، توسعهی روشهایی برای توضیحپذیر کردن مدلهای پیچیده یک ضرورت جدی برای آیندهی امن و قابل اعتماد هوش مصنوعی است.